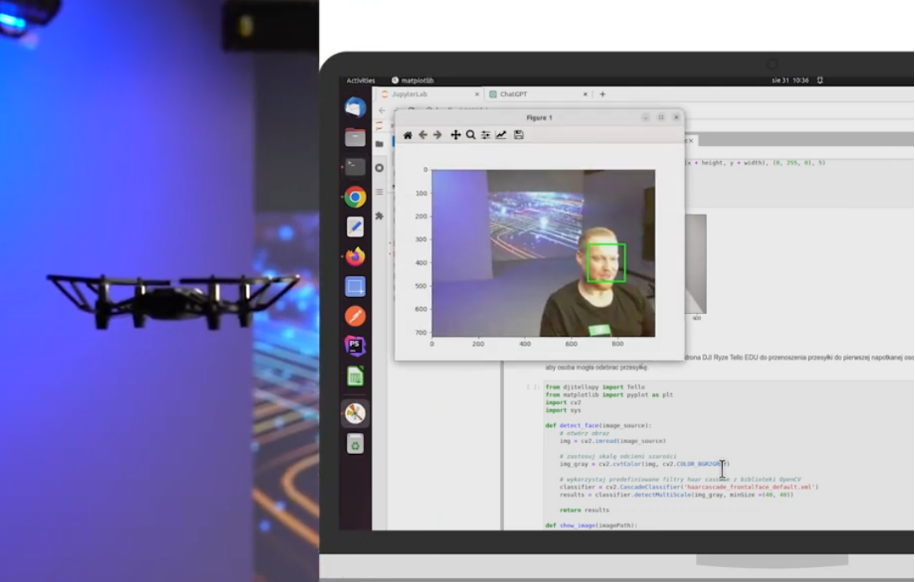
E-learning course: Machine learning – how to use the potential of data to get better results and make smart decisions
Posted on 3 January 2024 in projects
Course scenario:
- Definition and applications of machine learning
- Data deluge and the definition of machine learning
- Machine learning examples and related fields of knowledge
- Types of machine learning
- Machine learning tools used in the course
- Programs used in the course
- Orange Data Mining
- Jupyter Lab
- Supervised machine learning
- Machine learning process
- Data collection, labeling and analysis
- Feature engineering and division into training and testing sets
- Model training and evaluation
- Model export, corrective actions
- Regression example
- Classification example