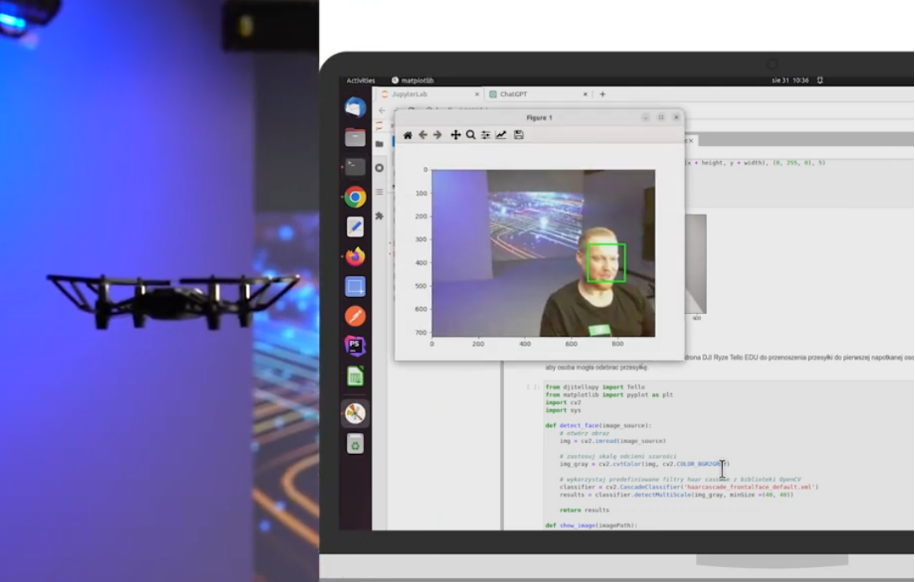
Posted on 3 January 2024
in projects
Course scenario:
- Definition and applications of machine learning
- Data deluge and the definition of machine learning
- Machine learning examples and related fields of knowledge
- Types of machine learning
- Machine learning tools used in the course
- Programs used in the course
- Orange Data Mining
- Jupyter Lab
- Supervised machine learning
- Machine learning process
- Data collection, labeling and analysis
- Feature engineering and division into training and testing sets
- Model training and evaluation
- Model export, corrective actions
- Regression example
- Classification example
more_link_text
AWS, CNN, langchain, LLM, Machine Learning, NER, NLP, Python, RAG, reinforcement learning, RNN, ScikitLearn, supervised ML, tensorflow, time series, unsupervised ML
Posted on 18 November 2023
in events
ML with PHP – replace complex business logic with machine learning models
Abstract: Have you ever encountered code with so many conditions and processing paths that it was almost impossible to maintain and extend? What if we replaced it with an automatically generated, self-improving algorithm? In recent years, machine learning as a field of artificial intelligence has become an effective tool for creating systems and applications. With the development of artificial neural networks, programming complex business rules and services based on prediction and classification can be replaced by pre-trained machine learning models. In this presentation, you will see a case study illustrating the potential of PHP in integrating machine learning. We will walk through the process of creating a classifier and placing it in a PHP-based project.
Docker, Machine Learning, NER, PHP, Python, tensorflow
[Top]
Posted on 27 May 2023
in events
Lecture: Exploring the viability of PHP for implementing artificial neural networks: A case study on autonomous vehicle control with CNN model
Abstract: In recent years, machine learning has become an essential tool for developing intelligent systems. With the rise of artificial neural networks, programming languages such as Python and R have become the go-to options for machine learning implementation. But is PHP a viable alternative? In this presentation, we will explore the potential of PHP for implementing artificial neural networks by examining its limitations compared to other popular languages. We will also demonstrate the application of machine learning in PHP through a case study where we trained a convolutional neural network model to control a prototype of an autonomous vehicle using Raspberry Pi and Nvidia’s “DAVE 2” CNN model architecture.
CNN, Machine Learning, PHP, tensorflow
[Top]
Posted on 26 January 2023
in projects
Responsibilities:
– prepare laboratories for students related to computing vision recognition and training autonomus vehicle using convolutional neural network and tensorflow library
– assemble vehicles using Raspberry Pi 4 Model B, motors and other parts
– configure environment for model training and run model on Raspbian OS
– implement module for object detection
CNN, Machine Learning, OpenCV, Python, tensorflow
[Top]
Posted on 1 November 2019
in projects
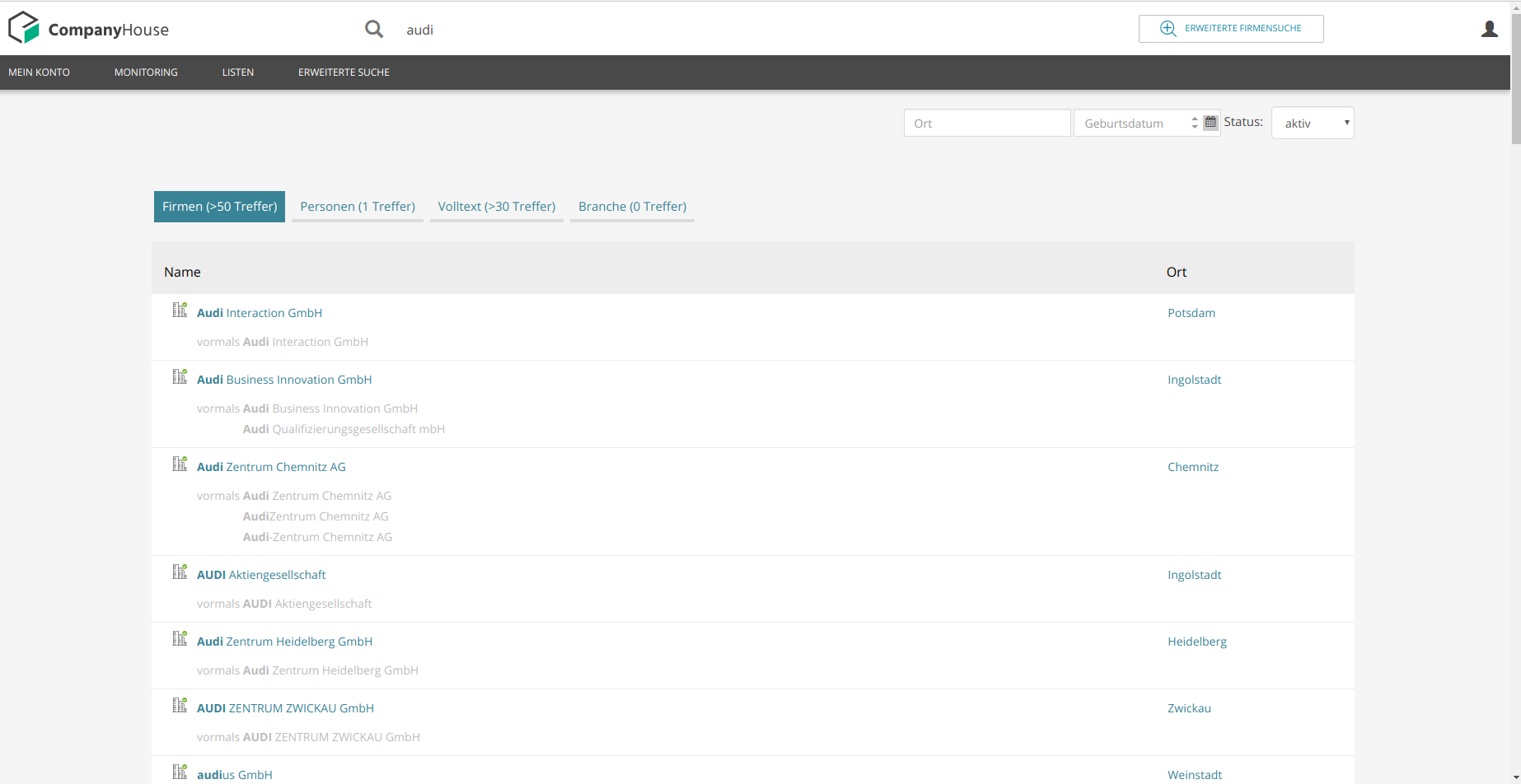
Pictures from companyhouse.de
Search engine based on Elasticsearch
Responsibilities:
- setup multi-node Elasticsearch server structure
- implementing efficient synchronization script
- configuring queries and score functions
Big Data, Elasticsearch, Kibana
[Top]
Posted on 24 February 2019
in projects
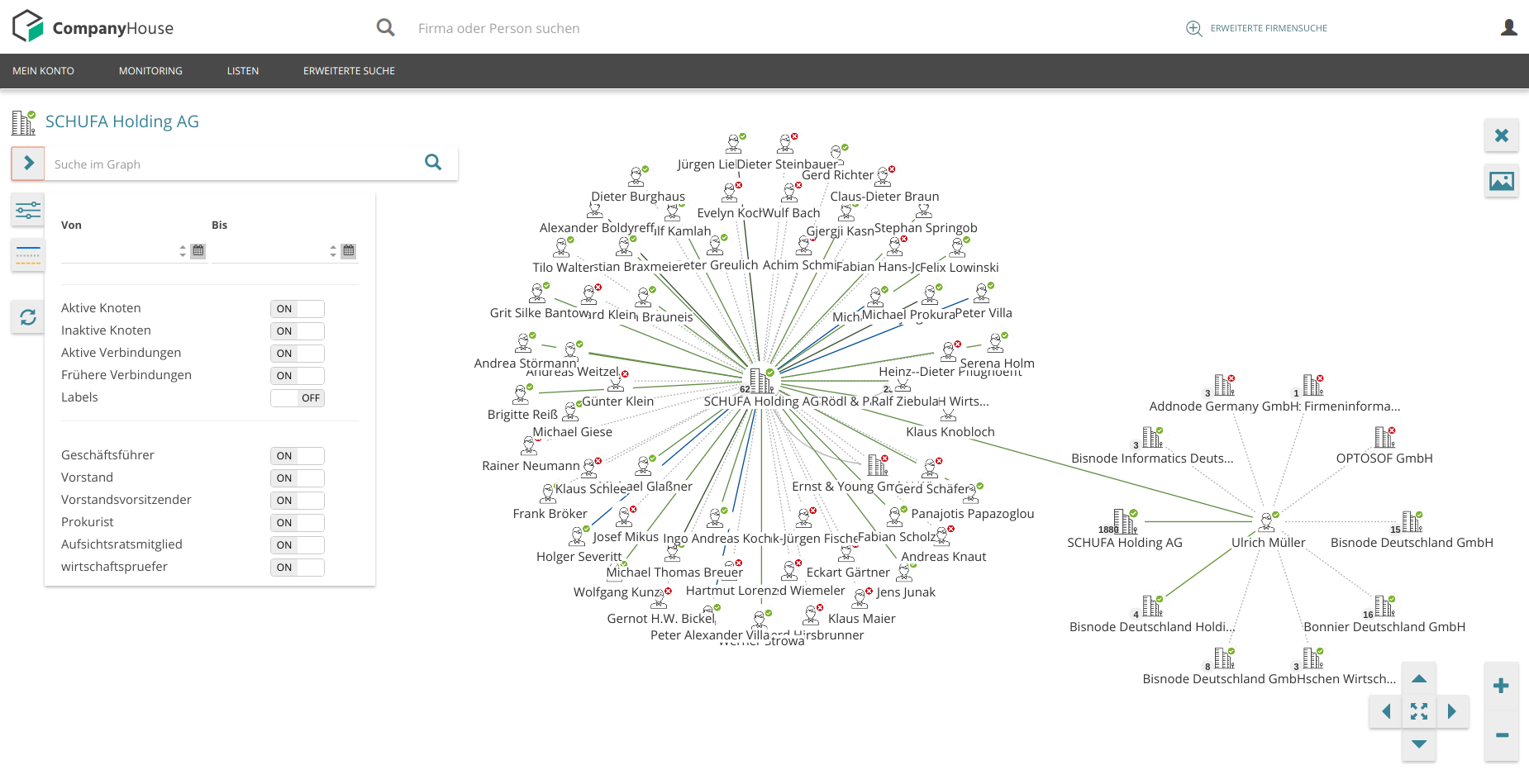
Pictures from companyhouse.de
Web application displaying and allowing to search, filter and export network graph
Responsibilities:
- Setup Neo4j graph db
- Implement data exporter, proxy and cache
- Implement network graph based on sigma.js library
- Support navigation, search and filtering graph
- Implement custom renderers for graph nodes and edges
- Implement nodes distribution algorithm
Elasticsearch, Neo4j, SigmaJS
[Top]
Posted on 24 February 2019
in projects

Machine learning model and web service predicting company industry codes based on description.
Responsibilities:
- Implement machine learning model classyfing text into over 100 classes
- German text preprocessing and normalization
- Evaluation and, upgrading model parameters
- Implement web service for real time prediction
Machine Learning, Python, ScikitLearn
[Top]
Posted on 30 December 2017
in projects

Banking and finances web portal about.
bs.net.pl
Responsibilities:
- Creating importer script to automatically get all data from old version based on drupal to new project
- implementing module for article publictaion on social pages: facebook, twitter
- Implementing new layout and widgets based
Centos, gulp, Jquery, nodejs, npm, PHP, PostgreSQL
[Top]
Posted on 1 July 2017
in projects
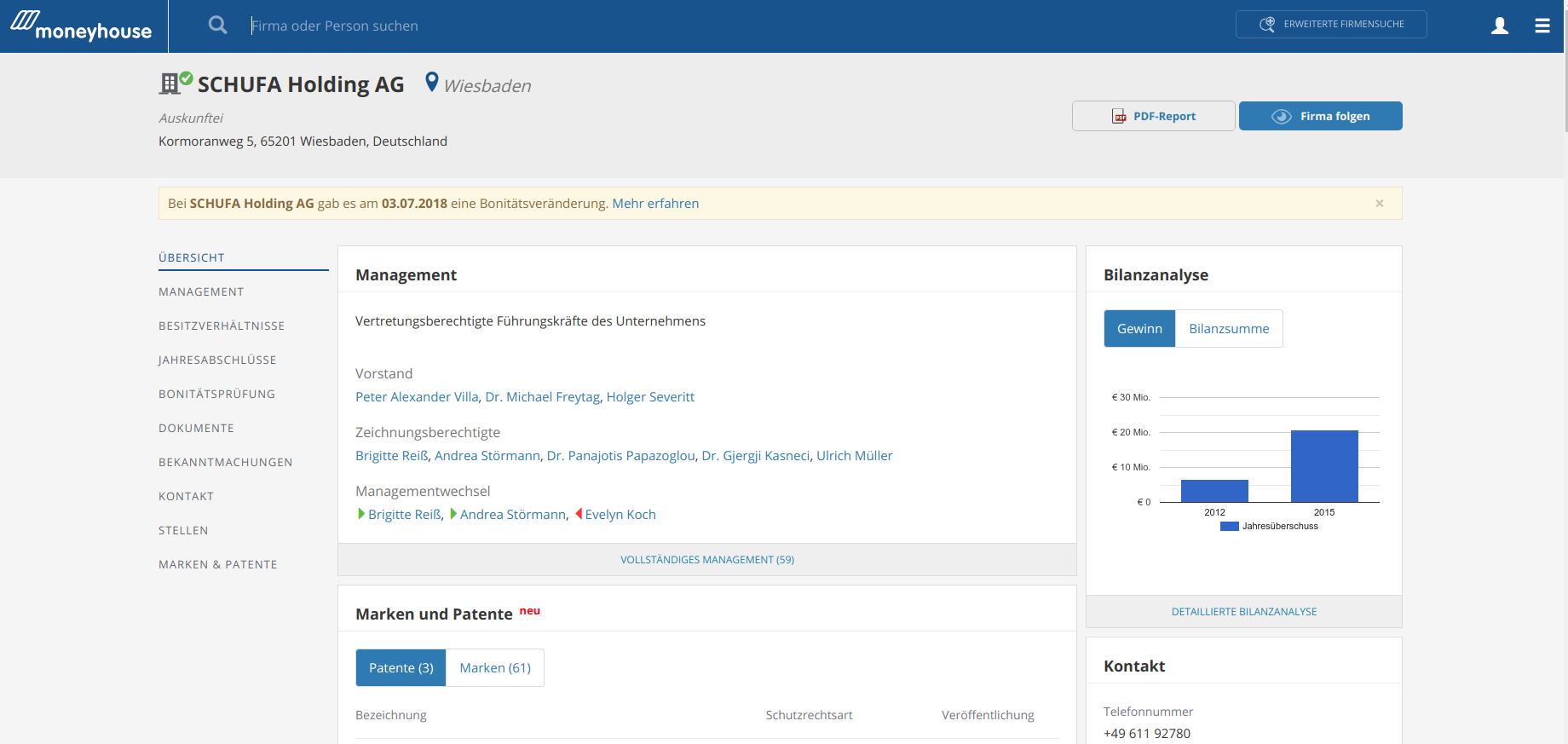
Pictures from moneyhouse.de
Web application to collect networking and finance data about German companies.
Responsibilities:
- Implementing data mining tools and parsers using deterministic algorithms and deep learning models
- creating fast and efficient search engine
- carrying out integration with external platforms, APIs, web-services
- working with Selenium, automation of acceptance, integration, functional and unit tests, TDD
- conducting data analysis using Python, R
- server environment setup and configuration
AWS, Cassandra, Data mining, data science, DBMS, Docker, Jenkins, Machine Learning, MongoDb, Neo4j, Neural networks, Nginx, NLP, NumPy, Pandas, PHP, regular expression, ScikitLearn, Server administration, Spacy, text mining, TextBlob, Ubuntu, Yii2
[Top]
Posted on 1 October 2016
in projects

Picture from programa.pl
Mobile application for Veolia workers to conduct Inspection of important equipment. Application is using web-service to pass data into cebtralized company system.
Responsibilities:
- implementing mobile application
- improving app transfer speed and data reliability
- implementing authentication methods and synchronization
- designing communication protocol
- application releases, updates and meintanance
Android, API
[Top]